首页
>
资讯
>
【周末杂谈】大模型推理的局限性
出自识林
【周末杂谈】大模型推理的局限性
2025-06-15
LLM和LRM随着任务复杂度的增加,会完全丧失推理能力
十天前,苹果公司的研发团队发布了一篇AI 研究论文。不愧是出自苹果之手,无论是新颖的方法论,让人意想不到的结果和结论,还是论文写作的精炼和插图的精美,都令人耳目一新。
笔者非AI专家,难以专业地对论文说三道四。下面只是对论文做简要介绍,有兴趣的读者可在网上查阅原文(The Illusion of Thinking: Understanding the Strengths and Limitations of Reasoning Models via the Lens of Problem Complexity)。
论文提出了一套深入、系统研究语言大模型(LLM)和推理大模型(LRM)推理轨迹和质量的方法论。创新点在提出了一组在维持整体逻辑不变的条件下,可控地逐步提高任务复杂度的应用场景和测试数据集,从而可定量、系统地研究大模型的推理过程和结果。论文的主要结论如下。
推理工作量随任务复杂度的增加而增加。但达到一定程度后,即使给足够的提示和算力,其推理工作量也会下降。也就是当任务复杂了,尽管多给提示和算力,大模型也会撂挑子。
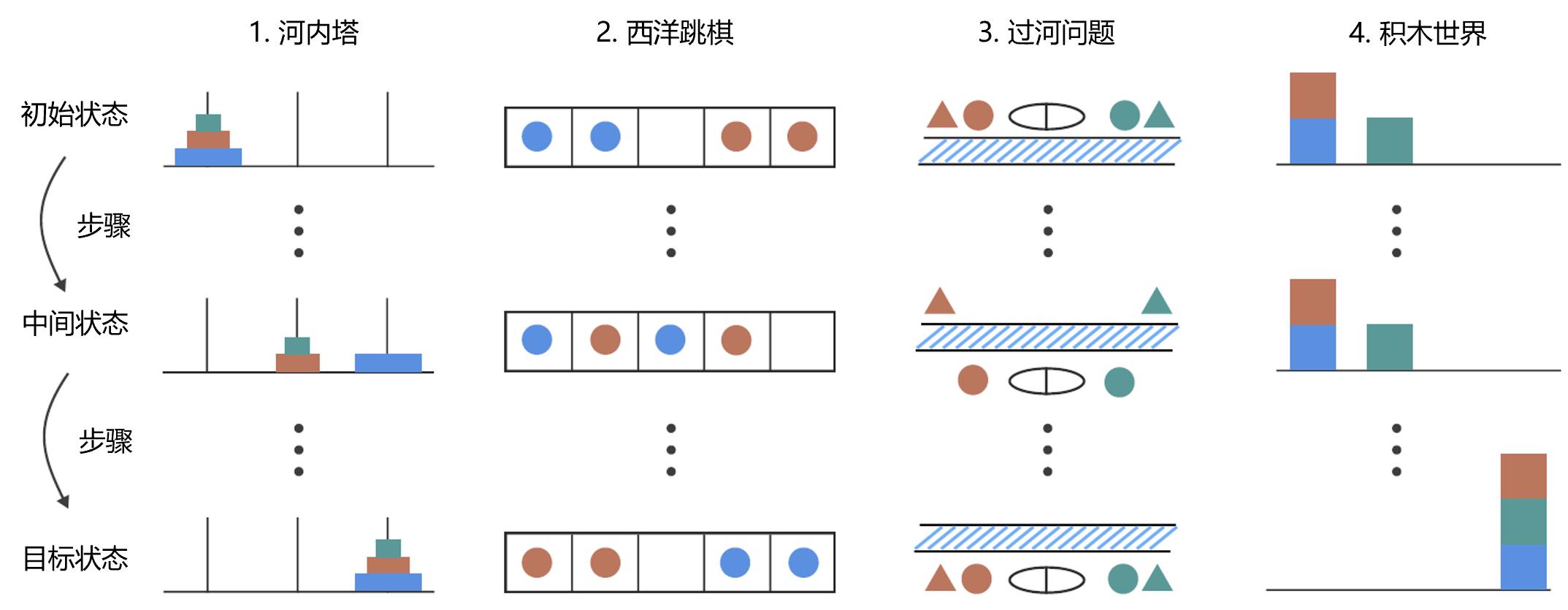
方法论所用的四组场景如下图所示。
场景1是河内塔游戏。有三个柱子,第一个柱子上叠放着三个大小不一的圆盘,小的在上。目标是将所有圆盘从第一个柱子移到第三个柱子。规则:一次只移动柱子顶部的圆盘,且不能将大圆盘放在小圆盘之上。游戏的复杂度可通过圆盘的数量来控制(图中显示的是n=3)。当圆盘数量为 n 时,所需的最小移动次数为 2n − 1。
场景2是西洋跳棋游戏。目标是交换所有橙色和蓝色棋子的位置,使其与初始位置保持镜像。规则:可将棋子滑入相邻的空白格,或跳过恰好一个颜色相同的棋子落入空白格,棋子不能后退。游戏的复杂度可通过棋子数量来控制。数量为 2n时,所需的最小移动次数为 (n + 1)² − 1。
场景3是过河游戏,n 位过河者及对应的 n 位代理。目标是将所有人从上岸运到下岸。船最多可载 k 人,且不能空载。过河者必须与自己的代理同船。游戏的复杂度可以通过数量n来控制。对于 n = 2 或 3 时,使用 k = 2 的船容量。n 更大时,使用 k = 3。
场景4是积木世界游戏。目标是将积木从初始状态重新排列成指定的状态,找出所需的最少移动次数。规则:只能移动堆叠最顶层的积木,积木可以放置在空堆叠上或其它积木之上。游戏的复杂度可通过积木数量 n 来控制。
论文的研究方法是将上述游戏规则告知大模型,看其是否找出目标结果。然后重复多次,算出找到目标结果的概率。概率越大,说明模型的推理能力越强。
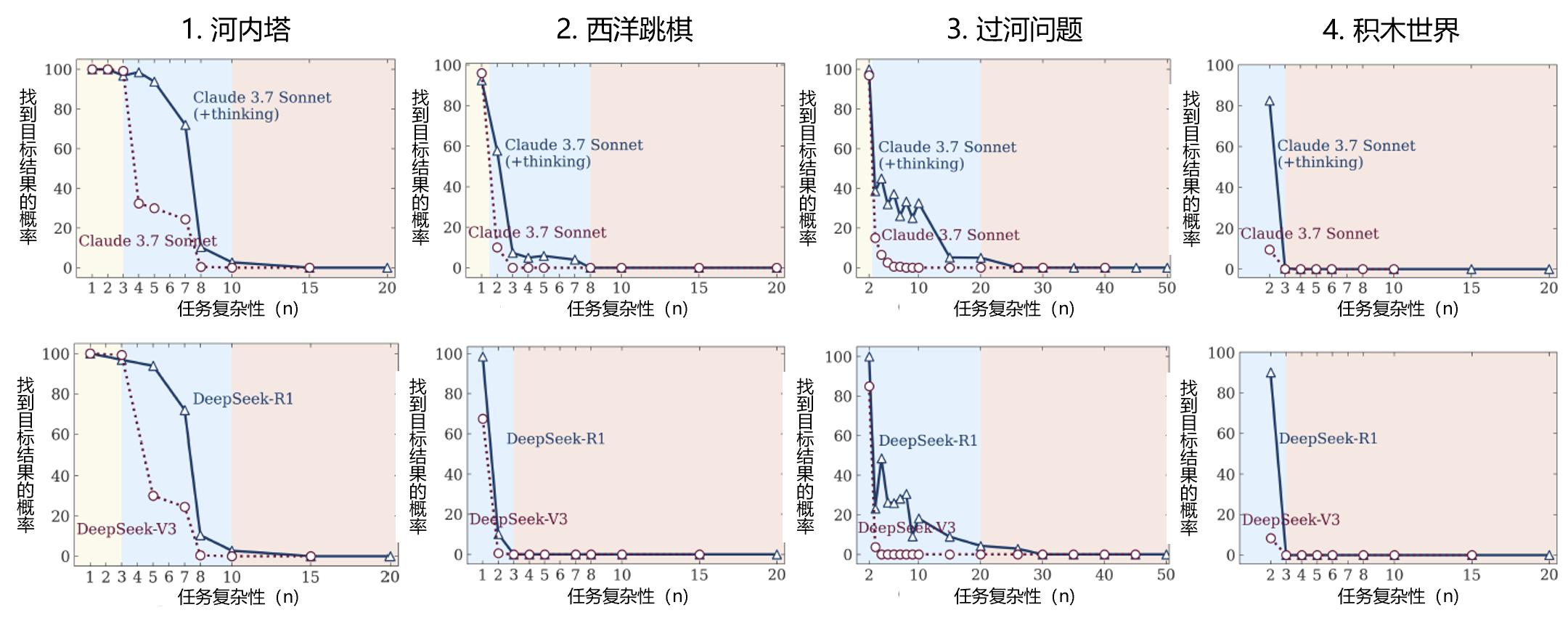
下图展示了两对LLM和LRM(Claude 3.7Sonnet及其推理模型,DeepSeek V3及其推理模型R1)在四种场景下,推理能力随任务复杂度的增加而产生的变化。如前所述,在所有场景下,在任务复杂度低时,LLM优于LRM。复杂度升高,LRM能力逐渐发挥并超过LLM,但总体结果均陡然下降。复杂度再高时,LRM和LLM均完全失去推理能力。
上图结果只是论文所有结果的一小部分。这是篇学术性论文,其中包含了场景、应用(提示词)、假设和使用条件的详细描述和讨论,并附有46篇参考文献的清单。
当然,上述结果只是在特定的场景下成立。如果把这些场景在不同复杂度下的模拟数据都放入大模型的训练集,那结果就可能不同。若果真如此,也说明大模型的推理基于的还是记忆而非智能。
识林-榆木疙瘩
识林® 版权所有,未经许可不得转载